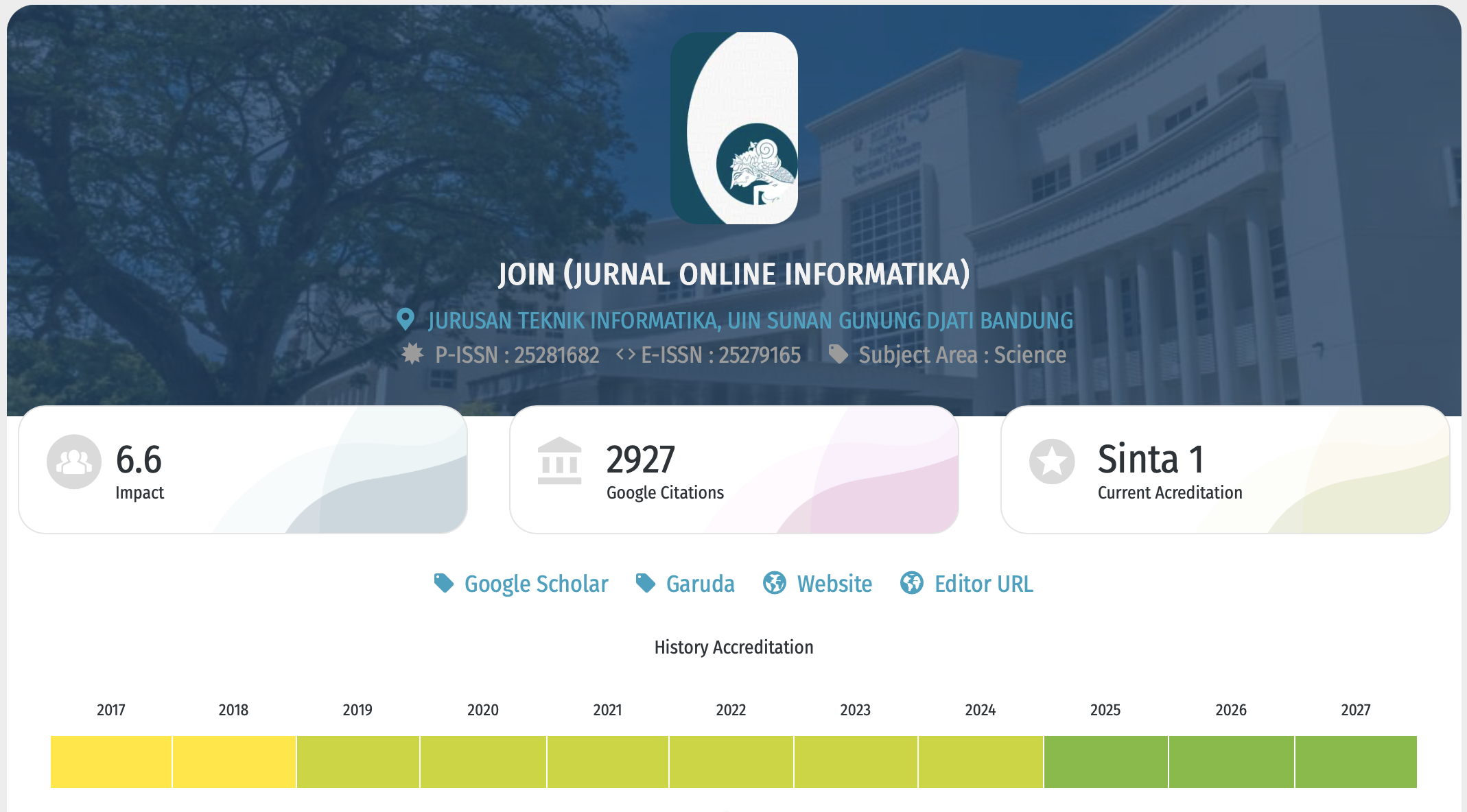
Multi Rule-based and Corpus-based for Sundanese Stemmer
DOI:
https://doi.org/10.15575/join.v7i2.846Keywords:
Corpus-based, Multi Rule-based, Stemmer, SundaneseAbstract
The purpose of this study is to develop a stemming method by involved several methods including morphological (with affix and pro-lexeme removal), syllable (canonical) pattern, and corpus data as a comparison of the final results of stemming. The algorithm checks a number of the string first and removes affixes, then check the syllable pattern according to the stripping result, then compares to the corpus data which determines the final stemming process. In this study, the corpus data was taken from Sundanese dictionary consists of a single word used for the root word and the extracted dataset from the online Sundanese magazine. The results showed that the stripping of affix and pro-lexeme can remove the corresponding affixes and pro-lexeme then compares words that have a syllable pattern then executes the basic words quickly and the use of corpus can improve accuracy and reduce the over-stemming problems that occur in the stemming process.
References
P. Willett, “The Porter stemming algorithm: then and now,†Program, vol. 40, no. 3, pp. 219–223, Jul. 2006, doi: 10.1108/00330330610681295.
M. Adriani, J. Asian, B. Nazief, S. M. M. Tahaghoghi, and H. E. Williams, “Stemming Indonesian,†ACM Trans. Asian Lang. Inf. Process., vol. 6, no. 4, pp. 1–33, Dec. 2007, doi: 10.1145/1316457.1316459.
A. Purwarianti, “A non deterministic Indonesian stemmer,†Proc. 2011 Int. Conf. Electr. Eng. Informatics, ICEEI 2011, no. October, 2011, doi: 10.1109/ICEEI.2011.6021829.
A. A. Damar, K. Dewi, and U. M. Siti, “Penerapan Algoritma Paice atau Husk untuk Stemming pada Kamus Bahasa Inggris ke Bahasa Indonesia,†J. Tek. Inform., vol. 6, no. 2, Oct. 2013, doi: 10.15408/jti.v6i2.2031.
A. S. Rizki, A. Tjahyanto, and R. Trialih, “Comparison of stemming algorithms and its effect on Indonesian text processing,†TELKOMNIKA (Telecommunication Comput. Electron. Control., vol. 17, no. 1, p. 95, Feb. 2019, doi: 10.12928/telkomnika.v17i1.10183.
Y. Anistyasari and E. Hariadi, “Algoritma Baru Pembentukan Kata Dasar Pada Proses Stemming Bahasa Indonesia,†Pros. SNRT (Seminar Nas. Ris. Ter., vol. 5662, no. November, pp. 70–76, 2019.
F. Amin and Purwatiningtyas, “Stemmer Bahasa Jawa Ngoko dengan Metode Affix Removal Stemmer (Rule Base Approach),†J. Teknol. Inf. Din., vol. 21, no. 1, pp. 16–24, 2016.
N. Hidayatullah, A. P. Wibawa, and H. A. Rosyid, “Penerapan ECS Stemmer untuk Modifikasi Nazief & Adriani Berbahasa Jawa,†vol. 3, no. 3, pp. 343–348, 2019.
R. Maulidi, “Stemmer Untuk Bahasa Madura Dengan Modifikasi Metode Enhanced Confix Stripping Stemmer,†in Prosiding Seminar Nasional FDI 2016, 2016, no. December, pp. 12–15.
G. Ngurah, M. Nata, and P. P. Yudiastra, “Stemming teks sor-singgih Bahasa Bali,†Konf. Nas. Sist. Inform. 2017 STMIK, no. Agustus, pp. 608–612, 2017.
M. Agus, P. Subali, C. Fatichah, and D. Informatika, “Kombinasi Metode Rule-Based Dan N-Gram Stemming Untuk Mengenali Stemmer Bahasa Bali,†J. Teknol. Inf. dan Ilmu Komput., vol. 6, no. 2, 2019, doi: 10.25126/jtiik.201961105.
D. Junaedi, O. Herlistiono, and D. Akbar, “Stemmer For Basa Sunda,†pp. 275–278, 2010.
A. Purwoko, “Model Stemming Berbasis kamus untuk dokumen berbahasa sunda,†INSTITUT PERTANIAN BOGOR, 2011.
A. A. Suryani, D. H. Widyantoro, A. Purwarianti, and Y. Sudaryat, “The Rule-Based Sundanese Stemmer,†ACM Trans. Asian Low-Resource Lang. Inf. Process., vol. 17, no. 4, pp. 1–28, Aug. 2018, doi: 10.1145/3195634.
A. Sutedi, R. Elsen, and M. R. Nashrulloh, “Sundanese Stemming using Syllable Pattern,†vol. 6, no. 2, pp. 218–224, 2021, doi: 10.15575/join.v6i2.812.
I. Baidillah et al., Direktori Aksara Sunda untuk Unicode, 1st ed. Dinas Pendidikan Provinsi Jawa Barat, 2008.
D. Sudaryat, Yayat, A. Prawirasumantri, and K. Yudibrata, Tata Basa Sunda Kiwari. Bandung: Yrama Widya, 2013.
L. S. Faznur et al., “Komparasi fonem bahasa sunda dan bahasa indonesia dalam buku teks,†Pena Literasi J. Pendidik. Bhs. dan Sastra Indones., vol. 2, no. 2, pp. 105–114, 2019.
R. A. Danadibrata, Kamus Basa Sunda, 4th ed. Bandung: Panitia Penerbitan Kamus Basa Sunda dan PT. Kiblat Buku Utama, 2015.

Downloads
Published
Issue
Section
Citation Check
License
You are free to:
- Share — copy and redistribute the material in any medium or format for any purpose, even commercially.
- The licensor cannot revoke these freedoms as long as you follow the license terms.
Under the following terms:
-
Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
-
NoDerivatives — If you remix, transform, or build upon the material, you may not distribute the modified material.
-
No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
Notices:
- You do not have to comply with the license for elements of the material in the public domain or where your use is permitted by an applicable exception or limitation.
- No warranties are given. The license may not give you all of the permissions necessary for your intended use. For example, other rights such as publicity, privacy, or moral rights may limit how you use the material.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License