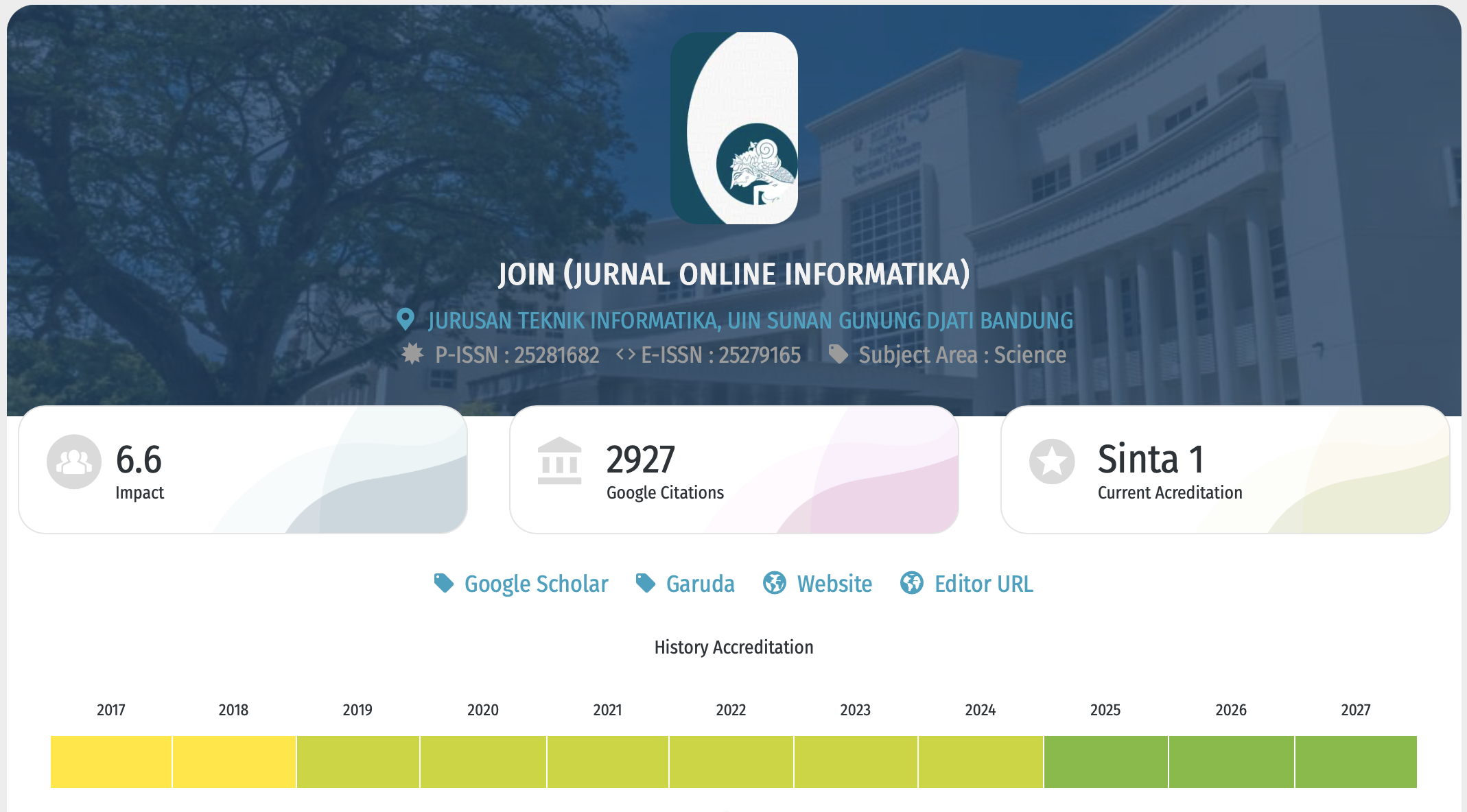
Random Forest Method Approach to Customer Classification Based on Non-Performing Loan in Micro Business
DOI:
https://doi.org/10.15575/join.v7i2.842Keywords:
Classification, Imbalanced Data, Improved random forest, Oversampling TechniqueAbstract
References
Bank Indonesia, “Profil Bisnis Usaha Mikro, Kecil, dan Menengah,†2015. www.bi.go.id.
Geev, “Mengenal Apa Itu UMKM dan Perkembangannya di Indonesia,†2017. .
Z. Arifin, Dasar-dasar Manajemen Bank Syari’ah. Jakarta: Alfabeta, 2002.
Bank Indonesia, Undang-Undang Nomor 10 Tahun 1998 tentang Perubahan Undang-Undang No. 7 Tahun 1992 tentang Perbankan. Jakarta: Gramedia, 1998.
Y. H. Fahmi, I and Lavianti, Pengantar Manajemen Perkreditan. Bandung: Bandung, 2010.
A. KumarM.N and H. S. Sheshadri, “On the Classification of Imbalanced Datasets,†Int. J. Comput. Appl., vol. 44, no. 8, 2012, doi: 10.5120/6280-8449.
P. Trkman, K. McCormack, M. P. V. De Oliveira, and M. B. Ladeira, “The impact of business analytics on supply chain performance,†Decis. Support Syst., vol. 49, no. 3, 2010, doi: 10.1016/j.dss.2010.03.007.
L. Breiman, “Random Forest,†Mach. Learn., vol. 45, no. 1, pp. 5–32, 2001.
L. Lin, F. Wang, X. Xie, and S. Zhong, “Random forests-based extreme learning machine ensemble for multi-regime time series prediction,†Expert Syst. Appl., vol. 83, pp. 164–176, Oct. 2017, doi: 10.1016/j.eswa.2017.04.013.
F. N. Koutanaei, H. Sajedi, and M. Khanbabaei, “A hybrid data mining model of feature selection algorithms and ensemble learning classifiers for credit scoring,†J. Retail. Consum. Serv., vol. 27, 2015, doi: 10.1016/j.jretconser.2015.07.003.
H. He, W. Zhang, and S. Zhang, “A novel ensemble method for credit scoring: Adaption of different imbalance ratios,†Expert Syst. Appl., vol. 98, 2018, doi: 10.1016/j.eswa.2018.01.012.
L. Breiman, “Manual on setting up, using, and understanding random forests v3. 1,†Tech. Report, http//oz.berkeley.edu/users/breiman, Stat. Dep. Univ. Calif. Berkeley, …, 2002.
P. Singh, S. and Gupta, “Comparative study ID3, cart and C4 . 5 Decision tree algorithm: a survey,†Int. J. Adv. Inf. Sci. Technol., vol. 27, no. 27, pp. 97–103, 2014.
A. Liaw and M. Wiener, “Classification and Regression with Random Forest,†R News, vol. 2, 2002.
D. Ramyachitra and P. Manikandan, “Imbalanced Dataset Classification and Solutions: a Review,†Int. J. Comput. Bus. Res. ISSN (Online, vol. 5, no. 4, 2014.
K. Santra and C. J. Christy, “Genetic Algorithm and Confusion Matrix for Document Clustering,†Int. J. Comput. Sci., vol. 9, no. 1, 2012.
M. Bekkar, H. K. Djemaa, and T. A. Alitouche, “Evaluation Measures for Models Assessment over Imbalanced Data Sets,†J. Inf. Eng. Appl., vol. 3, no. 10, 2013.
H. M and S. M.N, “A Review on Evaluation Metrics for Data Classification Evaluations,†Int. J. Data Min. Knowl. Manag. Process, vol. 5, no. 2, 2015, doi: 10.5121/ijdkp.2015.5201.
J. M. Johnson and T. M. Khoshgoftaar, “Deep learning and data sampling with imbalanced big data,†2019, doi: 10.1109/IRI.2019.00038.
M. Bramer, Principles of data mining fourth edition, vol. 30, no. 7. 2020.
A. Ali, S. M. Shamsuddin, and A. L. Ralescu, “Classification with class imbalance problem: A review,†Int. J. Adv. Soft Comput. its Appl., vol. 7, no. 3, 2015.
G. Louppe, L. Wehenkel, A. Sutera, and P. Geurts, “Understanding variable importances in Forests of randomized trees,†2013.
S. Wang and X. Yao, “Using class imbalance learning for software defect prediction,†IEEE Trans. Reliab., vol. 62, no. 2, 2013, doi: 10.1109/TR.2013.2259203.
X. Y. Liu and Z. H. Zhou, “Ensemble methods for class imbalance learning,†in Imbalanced Learning: Foundations, Algorithms, and Applications, 2013.

Downloads
Published
Issue
Section
Citation Check
License
You are free to:
- Share — copy and redistribute the material in any medium or format for any purpose, even commercially.
- The licensor cannot revoke these freedoms as long as you follow the license terms.
Under the following terms:
-
Attribution — You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
-
NoDerivatives — If you remix, transform, or build upon the material, you may not distribute the modified material.
-
No additional restrictions — You may not apply legal terms or technological measures that legally restrict others from doing anything the license permits.
Notices:
- You do not have to comply with the license for elements of the material in the public domain or where your use is permitted by an applicable exception or limitation.
- No warranties are given. The license may not give you all of the permissions necessary for your intended use. For example, other rights such as publicity, privacy, or moral rights may limit how you use the material.

This work is licensed under a Creative Commons Attribution-NoDerivatives 4.0 International License